轻声低语,藏在光芒下的语音转文字模型Whisper
ChatGPT的模型gpt-3.5-turbo发布当天,OpenAI还开源了一个语音转文本的模型:Whisper。但由于ChatGPT本身太过于耀眼,很多人都忽略了Whisper的存在。
我当时也是这样,我一度以为,Whisper也是一个API,需要发送POST请求到OpenAI的服务器上,然后它传回识别的结果。所以我很长一段时间一直都没有试用过这个模型。
直到前几天,我看到有人在少数派上面发了一篇文章,介绍他刚做的语音识别App,并且说这个App基于Whisper,完全不需要联网。我当时还奇怪,不联网你怎么调Whisper的API?于是我终于去认真了解了一下Whisper,发现它是OpenAI开源的语音转文字的模型,并不是API服务。这个模型只需要有Python就能本地离线运行,不需要联网。
Whisper的Github地址为:https://github.com/openai/whisper,在Python下用起来非常简单:
首先安装第三方库:
1 | python3 -m pip install openai-whisper |
接下来,在电脑上安装ffmpeg。以下是各种系统下的安装命令:
1 | # on Ubuntu or Debian |
以上就是全部的准备工作了。我们来测试一下这个模型的准确率有多高。下面是我的一段录音:
录音可以在公众号收听:
录音文件地址为:/Users/kingname/Downloads/公众号演示.m4a。那么编写如下代码:
1 | import whisper |
第一次加载模型时,它会自动去拉取模型文章。不同的模型文件大小不一样。拉取完成以后,后面再次使用就不需要联网了。
生成效果如下图所示:
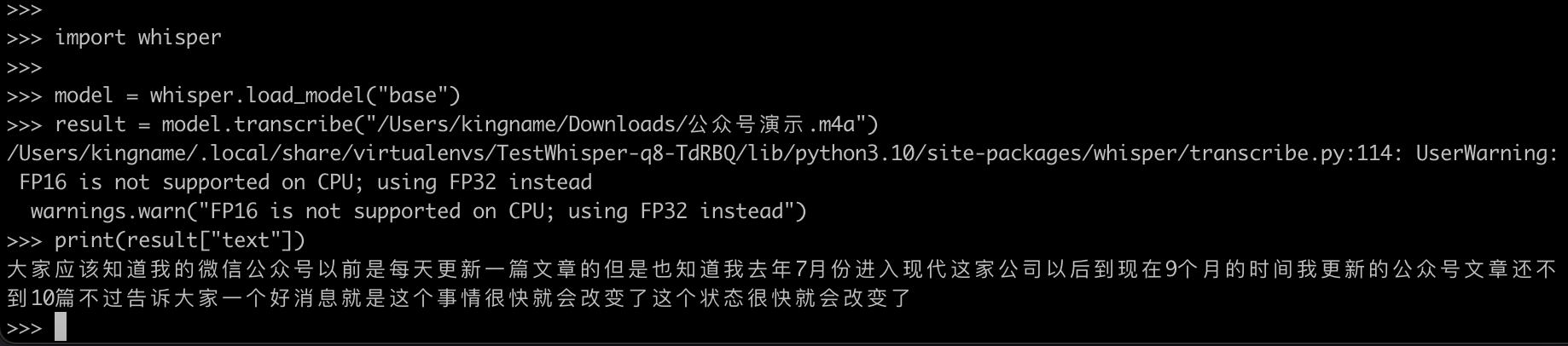
虽然有一两个错别字,但基本无伤大雅。更换更大的模型以后,准确率可以进一步提升:

我们知道,语音识别最麻烦的就是同音字,这种情况我们可以使用Whisper配合ChatGPT来进行纠正:
录音可以在公众号收听。

直接识别出来基本都是错别字,因为专有名词+同音字,必须通过联系上下文才能知道应该使用哪个字。我们让ChatGPT来改写一下:

经过测试,small模型对中文的识别效果已经非常好了,它运行起来会占用2GB左右的内存。速度也非常快。当我们想从一段视频里面把音频转成文字,或者自己做播客想生成字幕时,用这个模型就非常方便,完全免费,还不用担心自己的声音别泄露出去。
虽然Whisper是国外公司做的,但是它对中文的识别效果目前超过了国内许多大厂的中文语音识别产品。其中包括以语音识别著称的某飞公司,他们的产品效果经过测试没有Whisper好。这也说明了国内语音识别技术尚需进一步提升,需要更多的研究和开发。在这方面,国产货还有很大的努力空间,需要不断地探索和创新,以便更好地满足用户的需求。