一日一技:爬虫模拟浏览器如何避免重复登录?
当我们使用模拟浏览器访问一个网站的时候,可能会遇到网站需要登录的情况。我的爬虫练习网站提供了这样一个登录练习的案例。
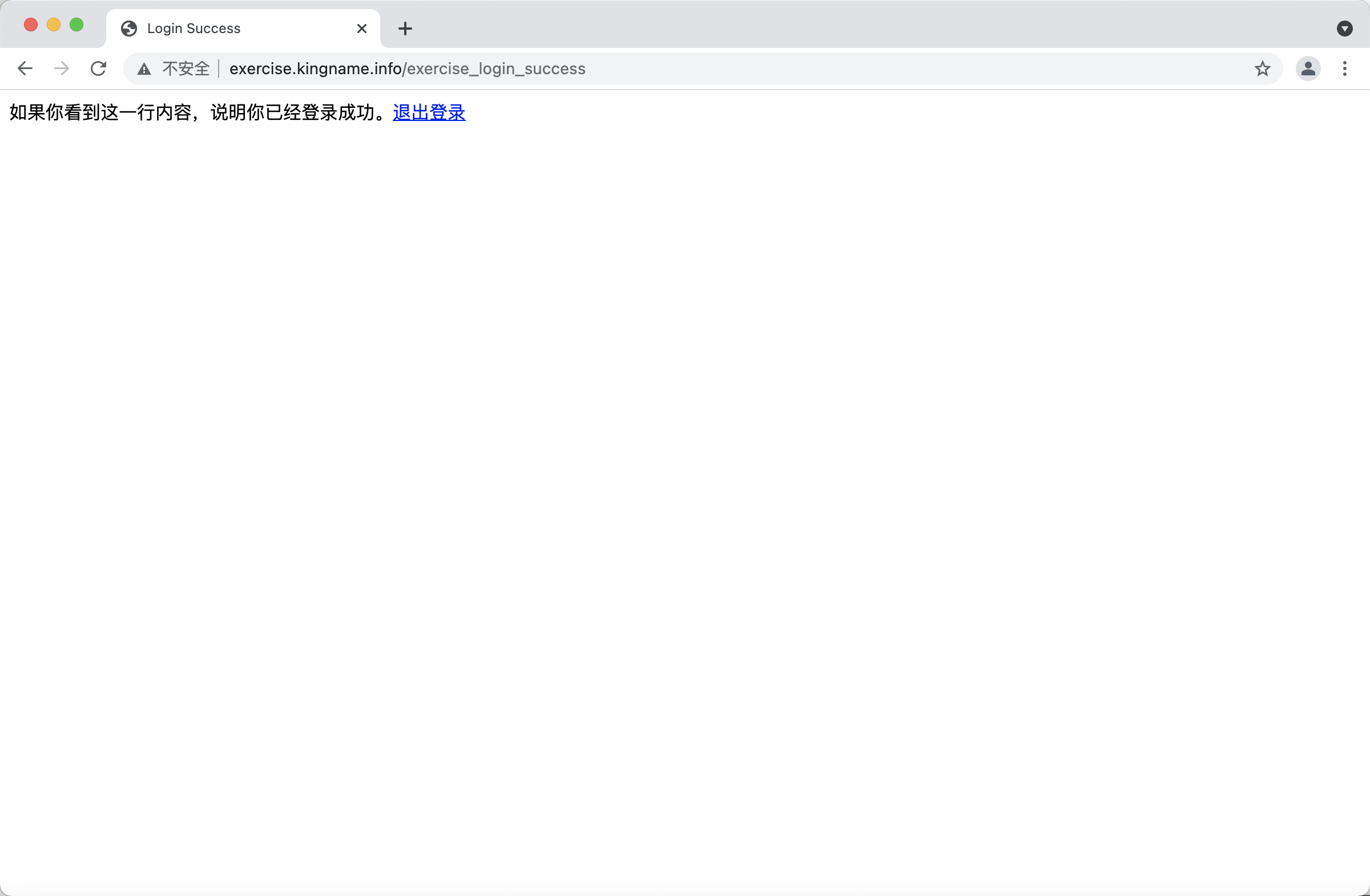
如果你手动用浏览器测试,你会发现这样一个现象:第一次访问的时候,自动跳转到登录页面。输入账号kingname和密码genius以后,可以看到登录成功的页面,如下图所示:
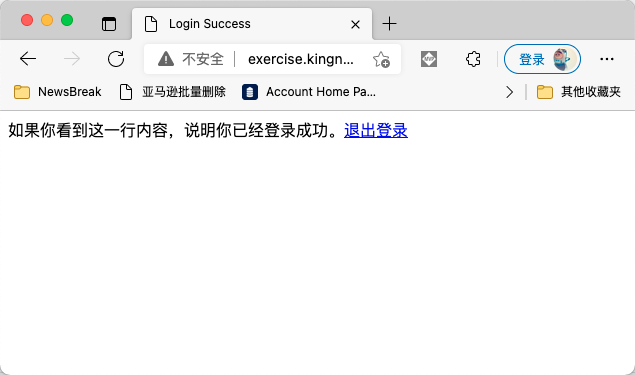
现在,你把浏览器关了再打开,然后再次访问这个网址,你会发现浏览器直接就能进入到登录成功的页面,不会再出现登录页面。
我们都知道,这是因为浏览器记住了网站的Cookies,即使关闭了浏览器再打开,这个Cookies依然存在,所以可以绕过登录功能。
但如果你使用Selenium或者Puppeteer/Pyppeteer,那么情况就不是这样了。当你第一次登录成功了以后,退出程序。第二次重新运行程序的时候,爬虫又要重新登录一次。这个过程一来拖慢了爬虫的运行速度,二来容易让网站检测到你的账号异常——难道自动登录功能失效了?为什么其他人的都正常,他的账号每小时都要重新登录一次?可能是爬虫,发个验证码过去探探虚实。
同理,还有时候,网站登录会出现很麻烦的验证码,但是一旦登录成功,这个验证码就再也不会出现了。处理这种验证码最简单的办法就是直接人工参与。那么如果爬虫每小时都要运行一次,岂不是每小时都要人来过一次验证码?能不能让爬虫只登录一次,之后就再也不登陆了呢?
方法有两个。第一个方法,也是大家最直观能想到的方法:登陆成功以后,把Cookies保存下来。下一次要重新登陆的时候直接把这个Cookies设置到浏览器里面可以了。这个方法网上有很多例子,你可以通过关键词“selenium 获取cookies”和“selenium设置cookies”搜索到,我就不再赘述了。
我们今天要讲的是第二个方法,也是最简单的方法。并且这个方法听起来很弱智:我不关浏览器,它的Cookies不就不会清空了吗?
但你仔细想一下,根据你之前的经验,当你的爬虫代码退出的时候,是不是浏览器也被自动关闭了?即使因为某种原因,爬虫代码本身崩溃了,浏览器没有关闭,那你第二次启动爬虫的时候,怎么重新连回之前启动的浏览器?
我们今天要做的,就是把启动浏览器和启动爬虫,这两件事情分开。首先使用某种方法单独启动浏览器,然后再启动爬虫代码,并且让爬虫代码接管这个浏览器并控制它。
Chrome浏览器是支持远程调试模式的。这个模式打开的情况下,Puppeteer或者Selenium可以通过websocket连上去,进而控制它。
首先我们来启动Chrome的远程调试端口。你需要找到Chrome的安装位置,在Chrome的地址栏输入chrome://version就能找到Chrome的安装路径,如下图所示:
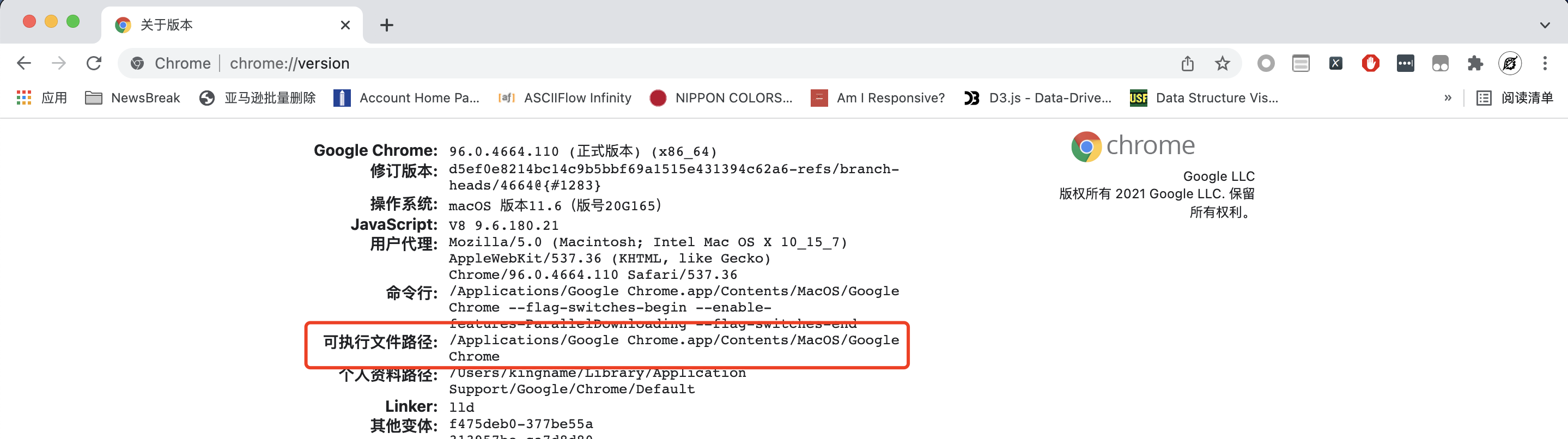
有了这个以后,我们需要执行命令启动支持远程调试功能的Chrome。如果你的电脑是Mac,那么命令是:
1 | "/Applications/Google Chrome.app/Contents/MacOS/Google Chrome" --remote-debugging-port=9222 --no-first-run --no-default-browser-check --user-data-dir=$(mktemp -d -t 'chrome-remote_data_dir') |
注意,由于地址中有空格,所以要把可执行文件的路径用引号抱起来。
如果你的电脑是Windows,那么就很简单了,执行命令:
1 | 文件路径/chrome.exe --remote-debugging-port=9222 |
启动以后如下图所示:
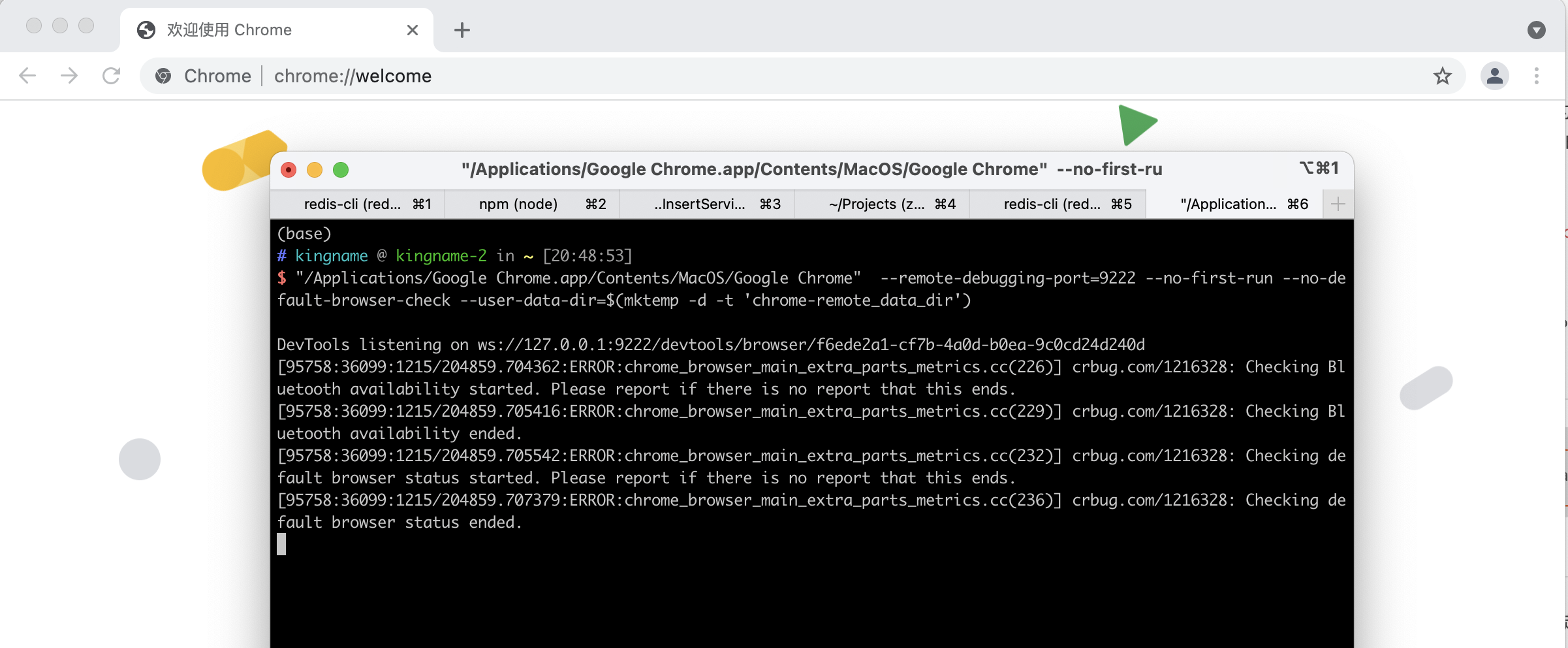
此时,你先不要动这个通过命令启动的Chrome。你先打开普通的浏览器,输入网址:http://127.0.0.1:9222/json/version,如下图所示:
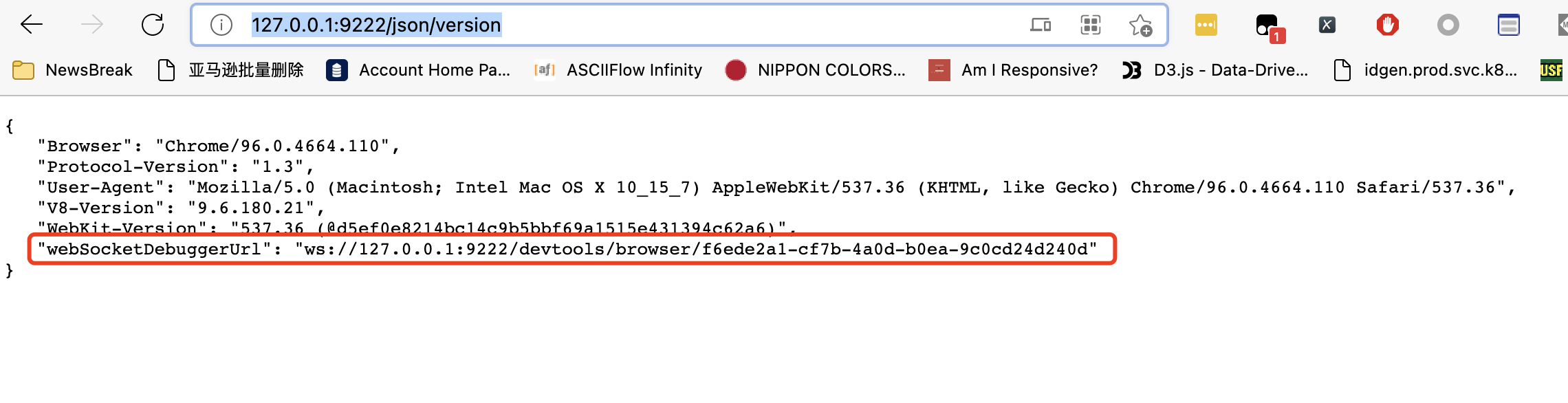
记住其中的webSocketDebuggerUrl后面的地址。这就是我们远程链接的地址。
今天我们以Puppeteer为例,介绍如何连接这个远程的Chrome。
在连之前,我们首先做一件事情,在通过命令启动的这个Chrome中,打开我们的登录练习页面,然后手动登录它。如下图所示:
然后,我们来写一段Puppeteer的代码:
1 | const puppeteer = require('puppeteer-core') |
这段代码最核心的就两行,连接远程的Chrome:
1 | var address = 'ws://127.0.0.1:9222/devtools/browser/f6ede2a1-cf7b-4a0d-b0ea-9c0cd24d240d' |
运行效果如下图所示:
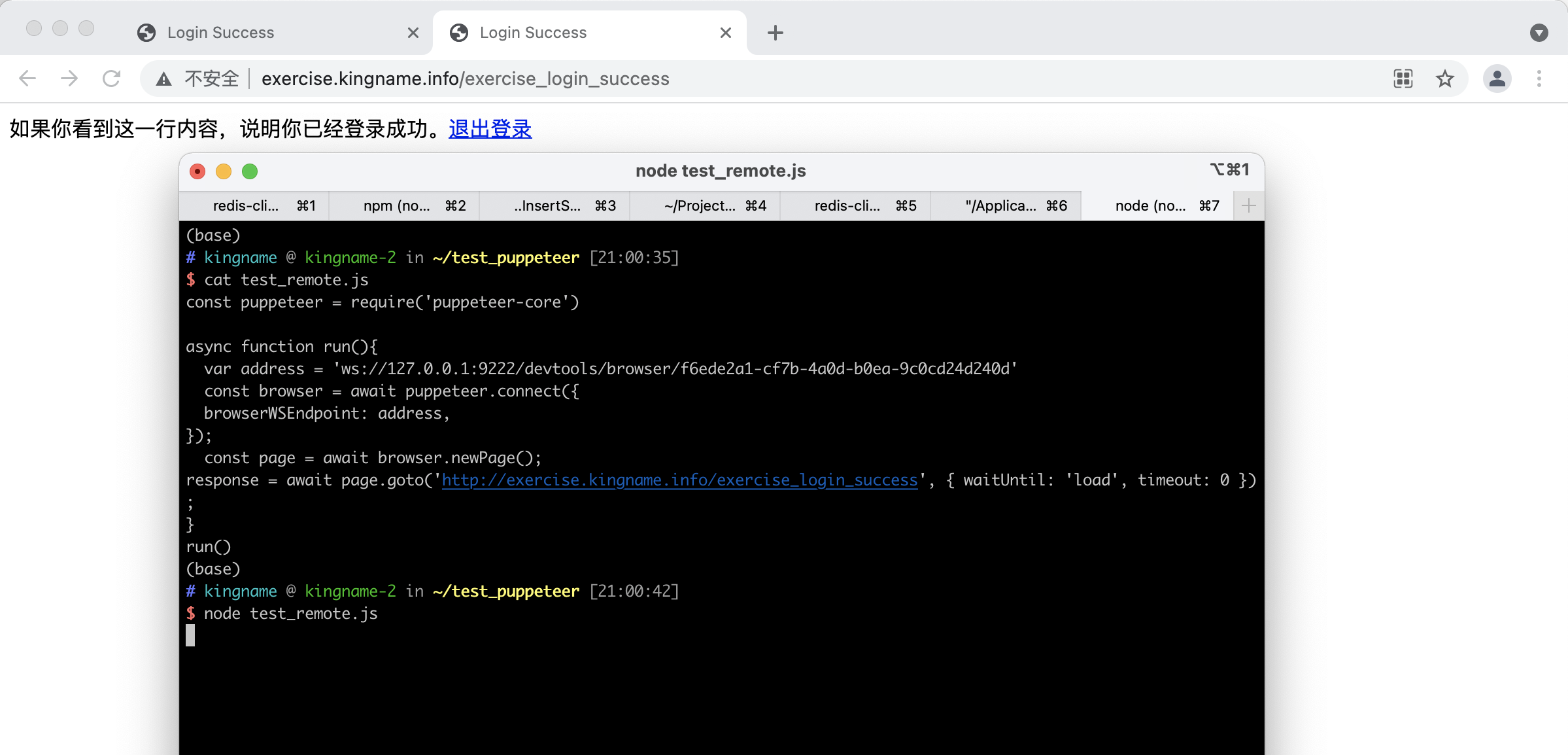
可以看到,代码控制浏览器打开了一个新的标签页,并且立刻就能打开登录成功后的页面,不需要再次登录。
大家可以试一试,现在在终端窗口里面按下Ctrl + C把当前的爬虫代码强行关闭,然后再启动一次,你会发现依然是登录以后的页面。
这样一来,以后遇到需要登录的网站,只需要使用这个远程调试模式,先启动一个支持远程调试的Chrome浏览器,然后手动在浏览器上完成登录操作,接下来爬虫代码就再也不需要考虑登录这个动作了,爬虫可以直接访问登录后的页面。
你自己测试的过程中,可能会发现标签页越开越多。其实不用担心,这是因为我为了演示登录后的页面,没有关闭当前标签页导致的。你的爬虫执行完操作以后,可以使用await page.close()关闭当前标签页。只要至少保留一个标签页不关闭,那么这个浏览器窗口就可以一直使用。