Kafka 里面的信息是如何被消费的?
作为一个爬虫工程师,Kafka 对你而言就是一个消息队列,你只需要掌握如何向里面写入数据,以及如何读取数据就可以m’ys’q作为一个爬虫工程师,Kafka 对你而言就是一个消息队列,你只需要掌握如何向里面写入数据,以及如何读取数据就何读取就可以可了。
请谨记:使用 Kafka 很容易,但对 Kafka 集群进行搭建、维护与调优很麻烦。Kafka 集群需要有专人来维护,不要以为你能轻易胜任这个工作。
本文,以及接下来的几篇针对 Kafka 的文章,我们面向的对象都是爬虫工程师或者仅仅需要使用 Kafka 的读者。关于 Kafka 更深入的底层细节与核心原理,不在我们的讨论范围中。为了解释方便,文章中对 Kafka 的一些术语会使用一些不太准确但能表明意思的类比。如果你需要在面试中解释这些术语,还请阅读Kafka 的官方文档。
今天我们要讨论的一个话题是,Kafka 是如何做到,对单个程序的多个进程而言,能持续消费,断点续传和并行消费;对多个程序而言又互不影响,各自独立。
一个 Kafka 可以有多个不同的队列,我们把这个队列叫做Topic,假设其中一个队列如下图所示:
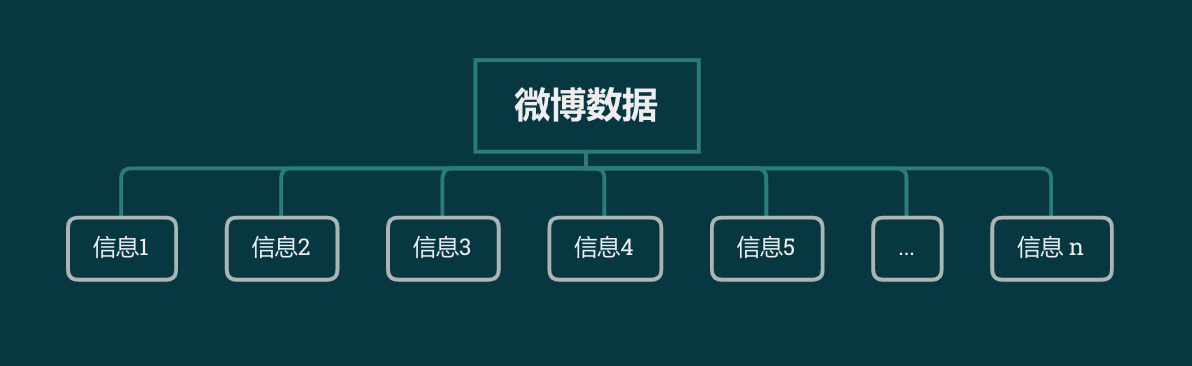
信息从右边进去,从左边出来。如果这是Redis 的列表,那么它弹出一条信息以后,队列会变成下面这样:
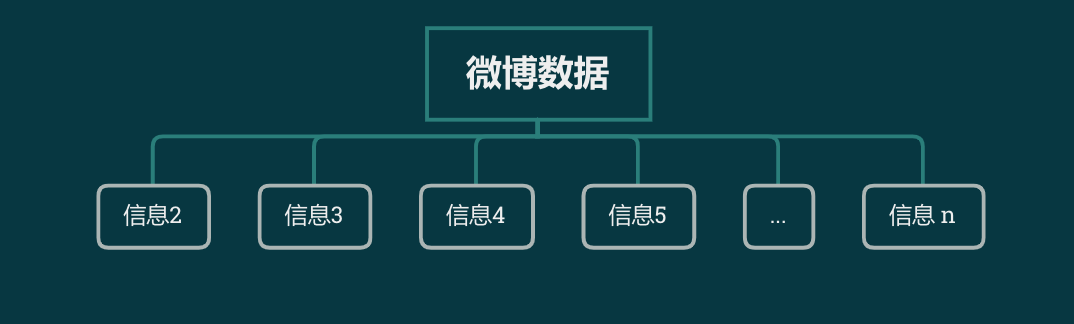
最左边的信息1不见了。所以即使程序在消费了信息1后立刻关闭,再重新打开,程序也会接着从信息2开始消费,不会把信息1重复消费两次。
但我如果有两个程序呢?程序1读取每一条数据,再转存到数据库。程序2读取每一条数据,再检查是否有关键词。这种情况下,信息1应该能被程序1消费,也能被程序2消费。但上面这种方案显然是不行的。当程序1消费了信息1,程序2就再也拿不到它了。
所以,在 Kafka 里面,信息会停留在队列里面,但对每一个程序来说,有一个单独的记号,来记录当前消费到了哪一条数据,如下图所示。
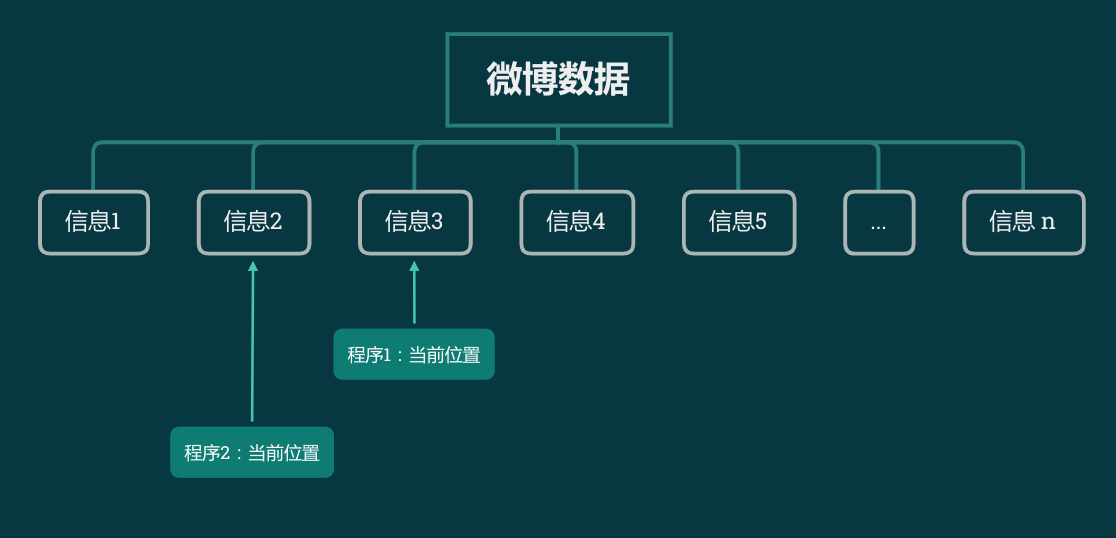
当程序1要读取 Kafka 里面下一条数据时,Kafka 先把当前位置的标记向右移动一位,把新的这个值返回出来。标记移动与返回这两个操作合在一起算是一个原子操作,不会出现重复读取的问题。
程序1与程序2使用的是不同的标记,所以各自的标记指向哪个值,是互不影响的。
当增加一个程序3的时候,只需要再加一个标记即可。新的这个标记也不受前两个标记的影响。
这就实现了在多个不同的程序读取 Kafka 时,各自互不影响。
现在如果你觉得程序1消费太慢了,把程序1同时运行了3次,那么由于标记和移位是原子操作,即使你看起来程序是同时去读取 Kafka,但在内部 Kafka 也会对他们进行“排队”,从而使得他们返回的结果不重复,不遗漏。
如果你在网上看 Kafka 的教程,你会发现他们提到了一个叫做 Offset 的东西,实际上就是本文所说的各个程序里面指向当前数据的标记。
你还会看到一个关键词叫做Group,实际上对应到本文的程序1,程序2和程序3。
对同一个队列,如果多个程序使用不同的Group消费,那么他们读取的数据就互不干扰。
对同一个队列,相同 Group 的多个进程在消费数据时,看起来就像是在对 Redis 进行 lpop 操作一样。
最后,你在网上关于 Kafka 的文章里面,一定会看到一个词叫做Paritition或者中文分片。而且你会发现你无法理解这个东西。
没关系,忘记它吧。你只需要知道,一个 Topic 有多少个 Partition,那么你最多能启动多少个进程读取同一个 Group。——如果一个Topic有3个Partition,那么你只能最多开3个进程同时读相同的 Group。 Topic如果有5个Partition,那么你只能最多开5个进程读同一个 Group。
下一篇文章,我们用 Python 来读写一下 Kafka。只需要几行代码。