一日一技:使用二分法排查正则表达式的异常
现在我有10亿条微博正文,并从同事手上拿到了15000条需要过滤的垃圾信息正则表达式,只要微博正文符合任何一条正则表达式,就删除这条微博。
正则表达式的格式为:
1 | ^你成功领取 |
存放在一个名为trash.txt的文本文件中,每个正则表达式一行。
一般情况下,我只需要使用如下几行代码就能实现这个功能:
1 | import re |
但是当我的代码运行到re.compile这一行时,报错了,如下图所示:

并且,即使你在 Google 上面搜索:re.error: multiple repeat at position,截至2019年12月30日,你能找到的都是对这个报错的讨论,但没有一个讨论能解决本文描述的问题。
那我们自食其力,来试着解决一下这个问题。它报错报的是position 167,那么我们来看看第167个字符有什么问题。在 PyCharm 中,可以在右下角查看你选中了多少个字符,如下图所示:
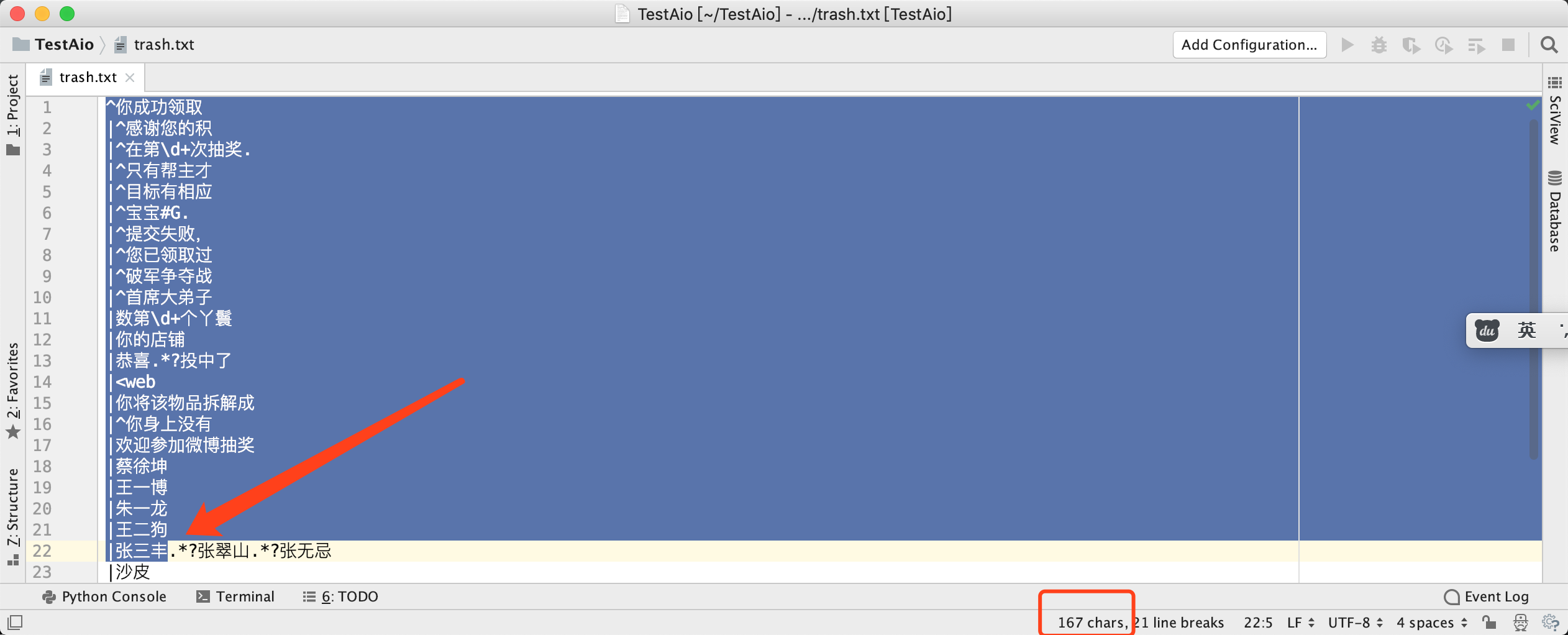
从截图中可以看到,第167个字符所在的这一行正则表达式为:|张三丰.*?张翠山.*?张无忌,但是我完全看不出这一行正则表达式有什么问题。
由于报错了,那么肯定至少有一行正则表达式有问题,我们假设有问题的正则表达式有且只有一行。现在我们有15000行正则表达式,如何找出有问题的这一行呢?
这个时候,我们就可以使用二分查找来解决这个问题,$log_{2}15000=13.8$,我们最多查找14次就能找到有问题的这一行正则表达式。
由于正则表达式一共有15000行,我们就先看0-7500行在编译时是否会报错,如果报错,在看0-3750行是否报错,如果不报错,在看3750-7500行是否报错……如此分割下去,直到找到报错的这一行正则表达式。
二分查找的代码如下:
1 | import re |
运行结果如下图所示:

原来出问题的地方在:.*??,这里多写了一个问号。把这一行改成|赵大.*?包以后,编译成功通过。
思考题
- 如果要把出问题的这一行所在的行号打印出来,应该如何修改代码?
- 如果有问题的正则表达式不止一行,应该如何修改代码,从而打印所有有问题的正则表达式?