炸掉你的内存—— itertools.tee 的弊端
在上一篇文章中,我们讲到了,使用itertools.tee可以让一个生成器被多次完整遍历:
1 | import itertools |
但是,我们说到itertools.tee有两个弊端,其一,如果分裂出来的多个生成器是按顺序执行的,其中一个完整遍历了再遍历第二个,那么就会导致内存中堆积大量的数据。
要解释这个问题的原因,我们就要理解itertools.tee背后的原理。
我们知道,一个生成器只能被完整遍历一次。那么如果我想强行让他被遍历两次怎么办呢?最简单的办法是搞个列表出来:
1 | g = generator() |
转换为列表以后,你想完整遍历几次,就能完整遍历几次。但这样做,就背离了使用生成器节省内存的目的。所有的数据,全都在列表里面,如果数据量非常非常多,那么内存可能就会爆炸。
所以我们需要一边迭代生成器,一边消费数据。为了实现这个目的,我们先来看看,如何一条一条地取出生成器里面的数据——next 函数。
当我们每次执行next(g)的时候,生成器被迭代1次,并返回1条数据,如下图所示:

当生成器的所有数据都被遍历完成以后,再次执行next(g)就会抛出StopIteration异常。所以当我们捕获到这个异常的时候,就说明生成器里面的所有数据都遍历完成了。
现在,我们把生成器分裂出来,但是取极端情况,只分裂1个。
1 | def generator(): |
运行效果如下图所示:
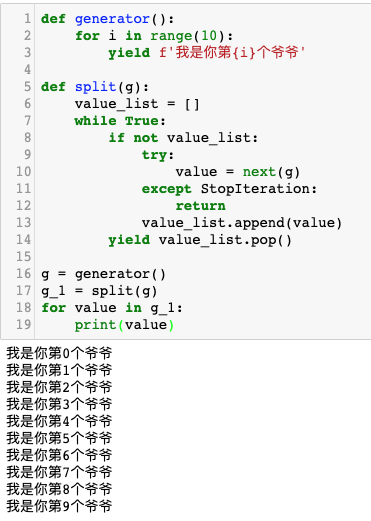
split生成器函数,写了一大堆代码,似乎做了无用功——如果value_list为空,那么就从原始生成器里面取一个数据,然后放入 value_list 列表,然后又把这个数从 value_list取出来,再抛给上层。
这样写有什么意义呢?
现在,我们修改代码,让 split 能够分裂出两个生成器:
1 | def generator(): |
运行效果如下图所示:

现在, split是一个会返回两个生成器的函数。首先创建两个列表value_list_1和value_list_2,然后定义一个闭包生成器函数wrap。它接收一个参数queue。这个参数是一个列表。
如果queue不为空,那么取它的第0个元素,并抛出给上层。如果queue为空,迭代一次原始生成器,获得的值同时放进value_list_1和value_list_2这两个列表中。此时,由于queue列表必定是value_list_1或者value_list_2的其中一个,所以此时queue必定不为空,因此可以取它下标为0的元素,抛出给上层。
由于.pop在取出数据以后,会把这个数据从列表里面删除。所以queue对应的列表又会变成空。
但大家有没有发现,此时,另外一个列表的数据,是留在列表里面的,没有被消费。
所以,如果我始终迭代g_1这个分裂后的生成器,那么wrap的参数始终是value_list_1,此时,value_list_2始终没有被消费,于是数据就会越堆越多,最后撑爆内存。
所以,itertools.tee分裂以后的多个生成器,应该尽量间隔着迭代,或者“同时迭代”,例如:
1 | while True: |
这样调用,就能始终保证两个列表最多只有1条数据,就不会出现堆积的问题。
但是在实际项目中,很难这样写,所以你可能会想,是不是可以把分裂后的多个生成器,放进多个线程里面同步运行。这样虽然列表里面的数据会超过1条,但也不会堆积太多。
然而这是不行的,itertools.tee分裂出来的多个生成器不是线程安全的,不能在多线程里面运行,否则会导致报错。这里给出一个报错的例子:
1 | import itertools |
运行效果如下图所示:
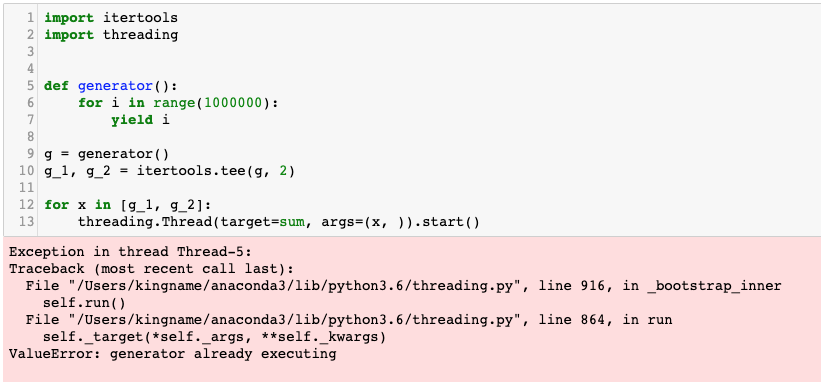
在下一篇文章中,我们将会说明,为什么分裂以后的生成器不是线程安全的,以及如何让它线程安全。
P.S.:本文介绍 itertools.tee的代码经过简化和修改,用于表示这个函数的核心逻辑。但真正的源代码比这个简化版本要复杂得多。并且源代码中队列是使用dequeue而不是列表。因为dequeue是基于双向链表实现的,在两头增加删除数据,时间复杂度都是 O(1),但是从列表的头部删除数据,时间复杂度为 O(n)。