使用etree.HTML的编码问题
出现问题
今天指导一个学生爬取新浪体育手机版的时候,发现lxml.etree.HTML处理网页源代码会默认修改编码,导致打印出来的内容为乱码。爬取的网址为:http://sports.sina.cn/nba/rockets/2015-10-07/detail-ifximrxn8235561.d.html?vt=4&pos=10
首先导入我们需要用到的库文件,然后设置环境:
1 | #-*_coding:utf8-*- |
然后获取网页的源代码:
1 |
|
打印出网页源代码,发现中文是乱码,如图:
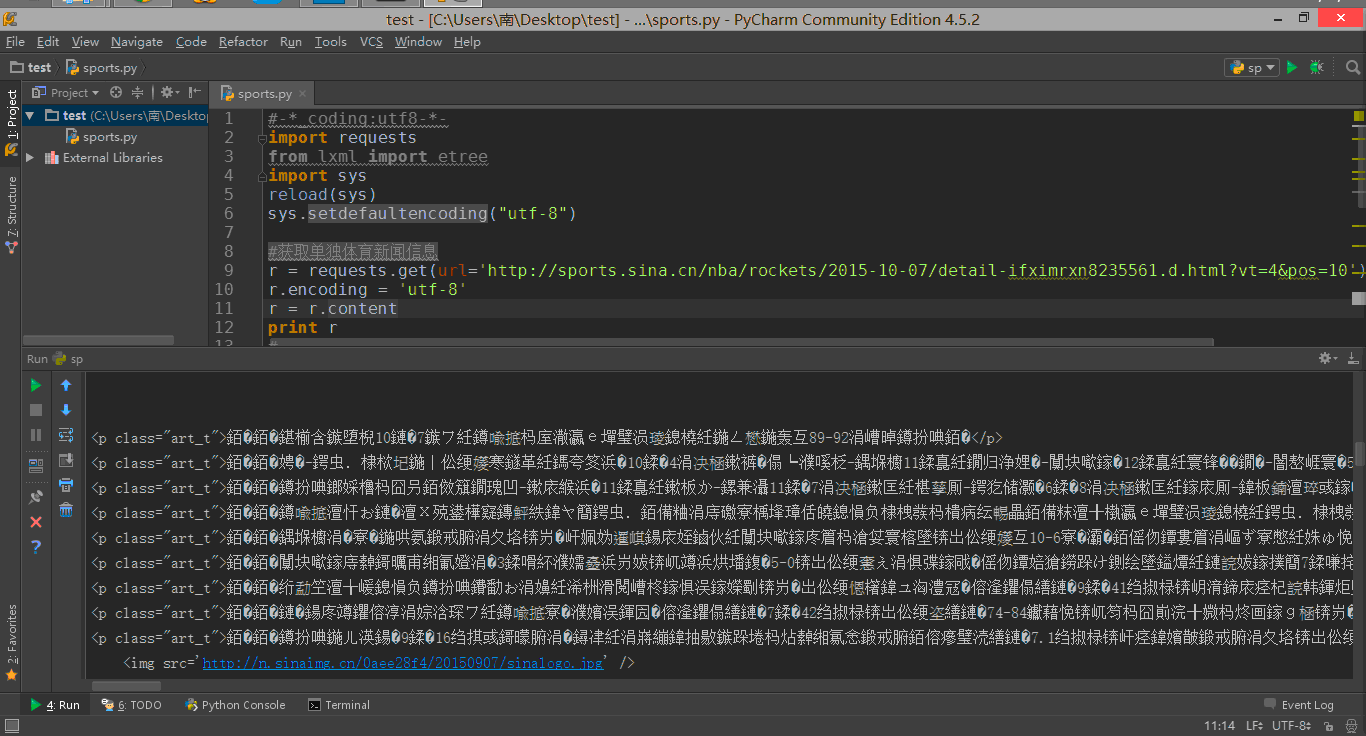
这是小问题,使用Python字符编码的一个相对万能的处理方法这篇文章中讲解的方法,轻松解决。
将:
1 | r = r.content |
修改为:
1 | r = r.content.decode('utf-8').encode('gbk') |
可以正常显示中文,如图:
接下来,使用etree.HTML处理源代码,然后使用Xpath提取内容,一切似乎看起来轻车熟路。

1 | contentTree = etree.HTML(r) |
但是当我打印出来,才发现问题没有这么简单。如图:
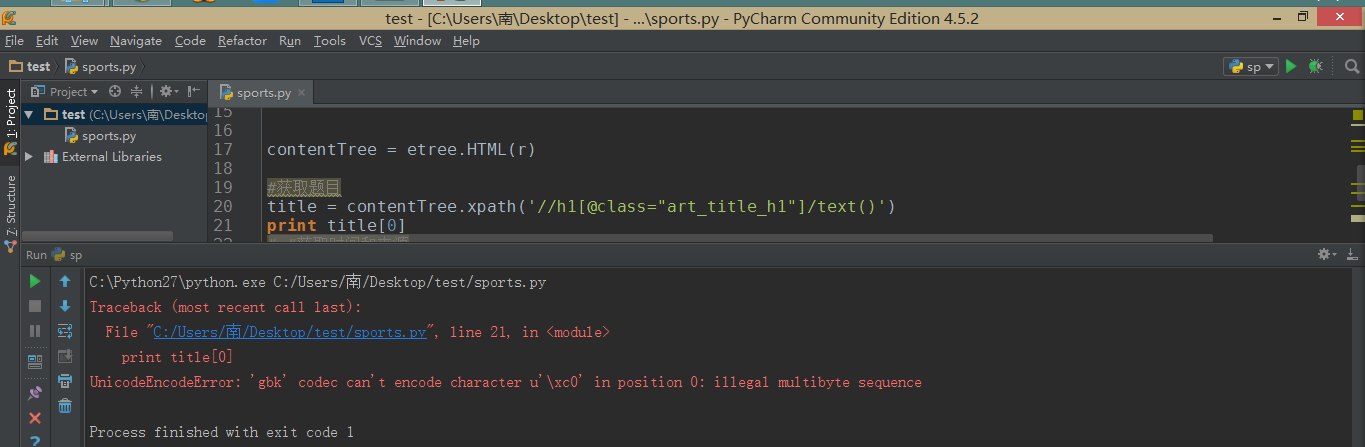
这个时候,我发现使用Python字符编码的一个相对万能的处理方法讲到的办法已经不能解决问题了。
通过调试,我发现抓取到的内容是乱码:
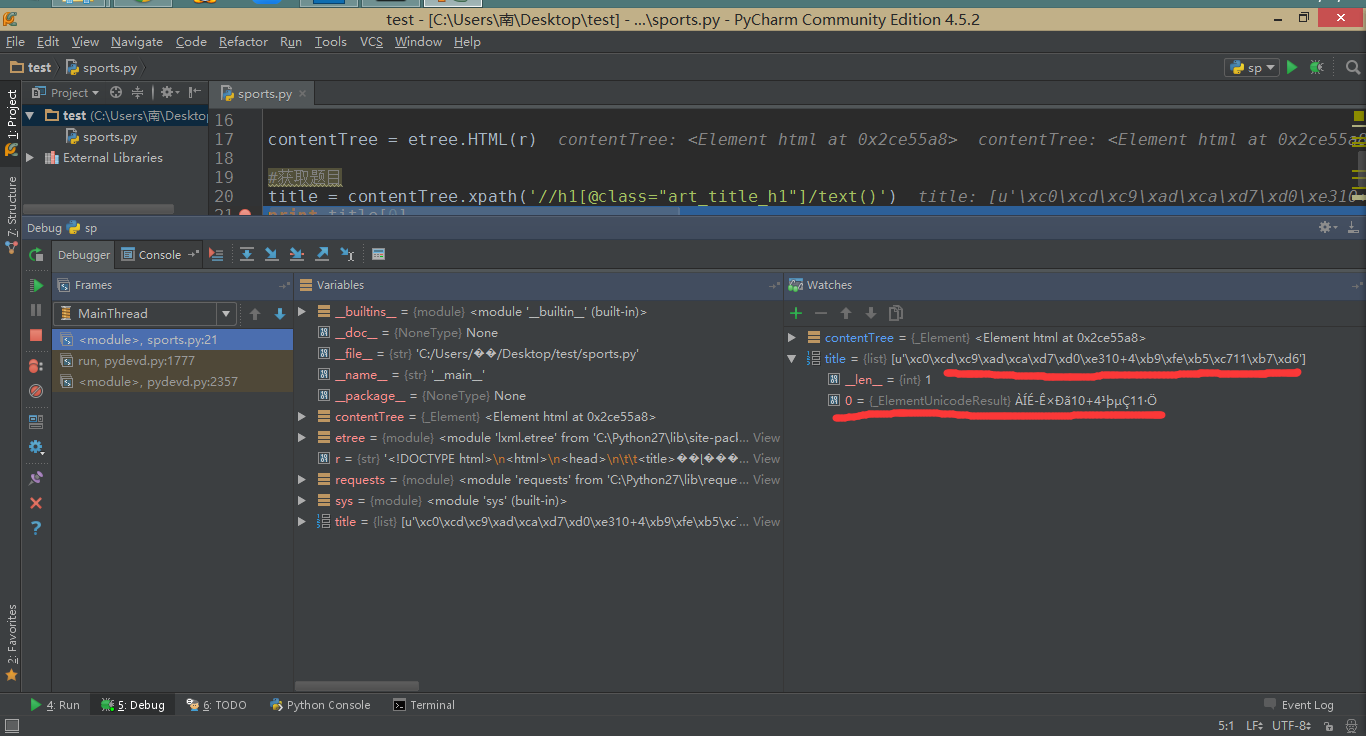
解决办法
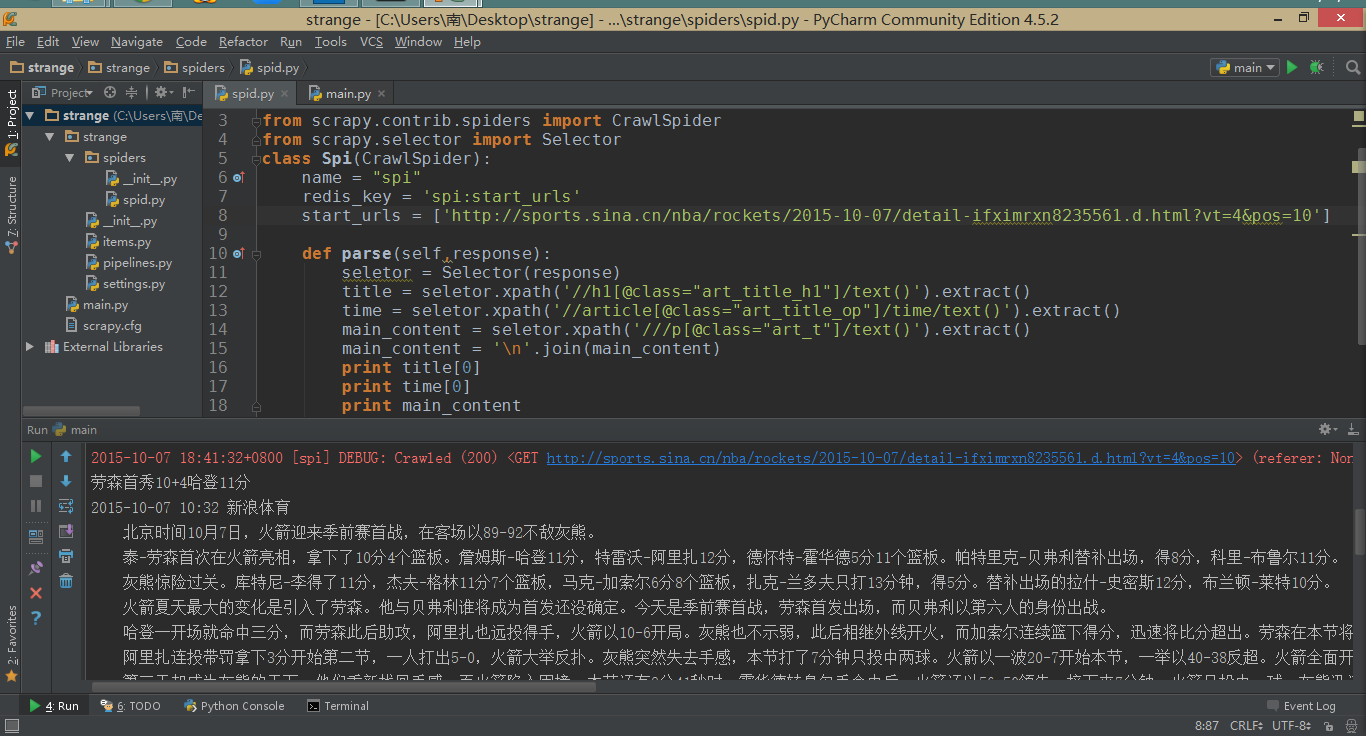
使用Scrapy
使用Scrapy的Xpath,正常提取需要的内容:
继续用etree
实际上,Scrapy的Xpath底层还是调用的lxml,那为什么它可以,而我直接使用lxml的etree.HTML处理源代码然后Xpath提取内容就出乱码呢?
显然这应该是编码的问题,在使用:
1 | etree.HTML(r) |
处理源文件的时候,由于没有指定编码,所以它使用了一个默认编码,从而导致和UTF-8冲突,产生乱码。
经过查阅lxml.etree.HTML的文档,我发现etree.HTML有一个参数是parser,这个参数不是必须的,因此省略以后它就会自动使用一个默认的parser。既然如此,那我手动指定一个:
1 | contentTree = etree.HTML(r, parser=etree.HTMLParser(encoding='utf-8')) |
这里我指定了etree.HTMLParser来作为一个parser,同时,etree.HTMLParser可以接受编码作为参数。于是我指定为UTF-8。
运行看看效果:
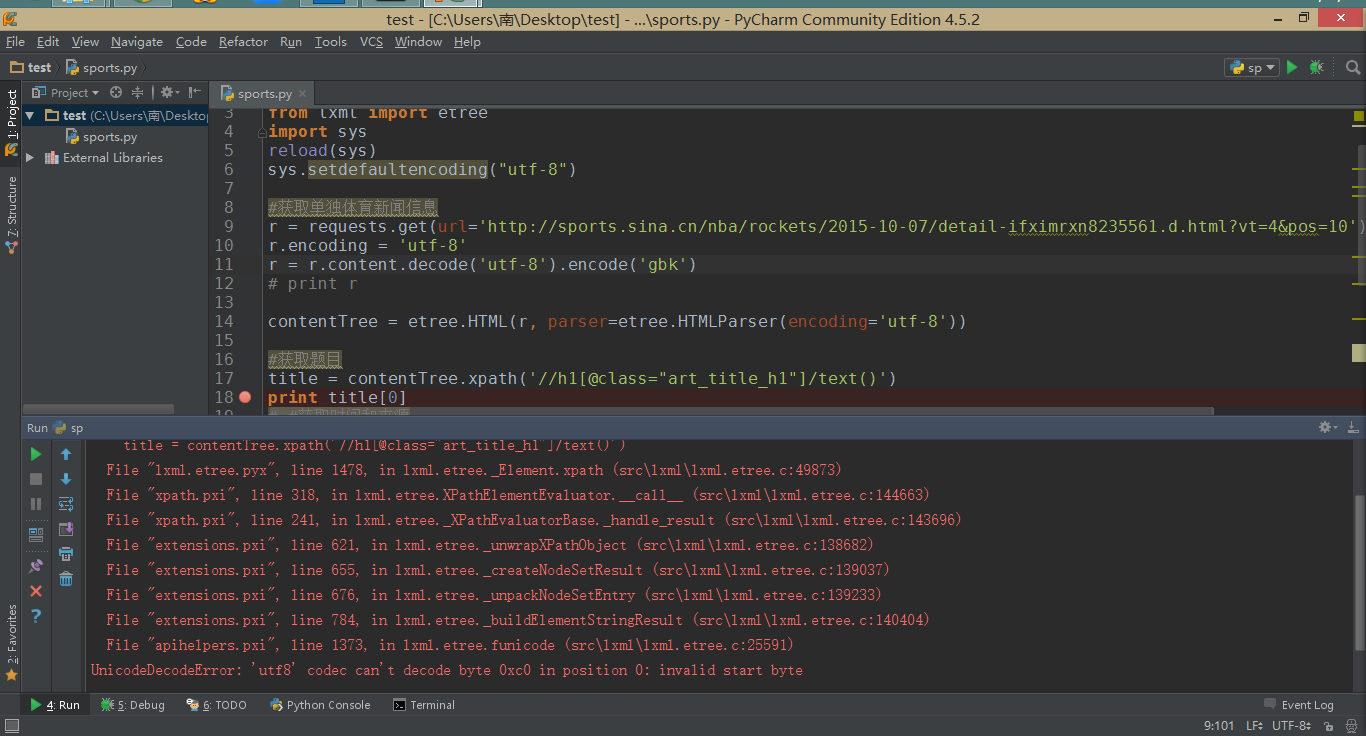
继续报错,但是出错信息改变了,提示utf8不能解码。请注意第11行,现在源代码是gbk编码,所以使用UTF-8不能解码。于是可以把第11行重新改回原来的样子:
1 | r = r.content |
再一次运行,发现正常抓取信息:
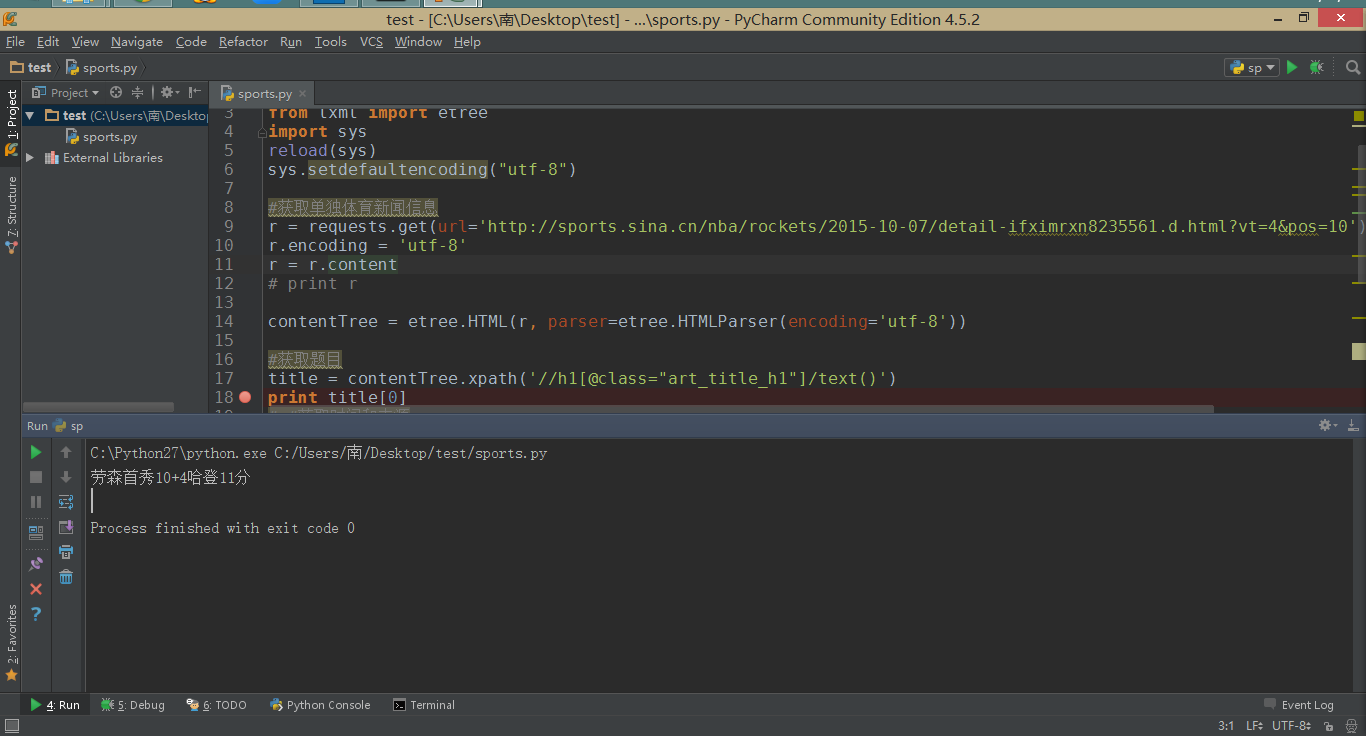
总结
这一次的问题提示我们:遇到问题,通过经验解决不了的时候,请回归文档。
原文发表在:http://blog.kingname.info/2015/10/07/lxmlencoding/转载请注明出处!