2018.09
由于Python是动态语言,不需要为变量提前设定类型,这为开发提供便捷的同时也带来了一些麻烦。
有这样一段代码:
1 | class Robot(object): |
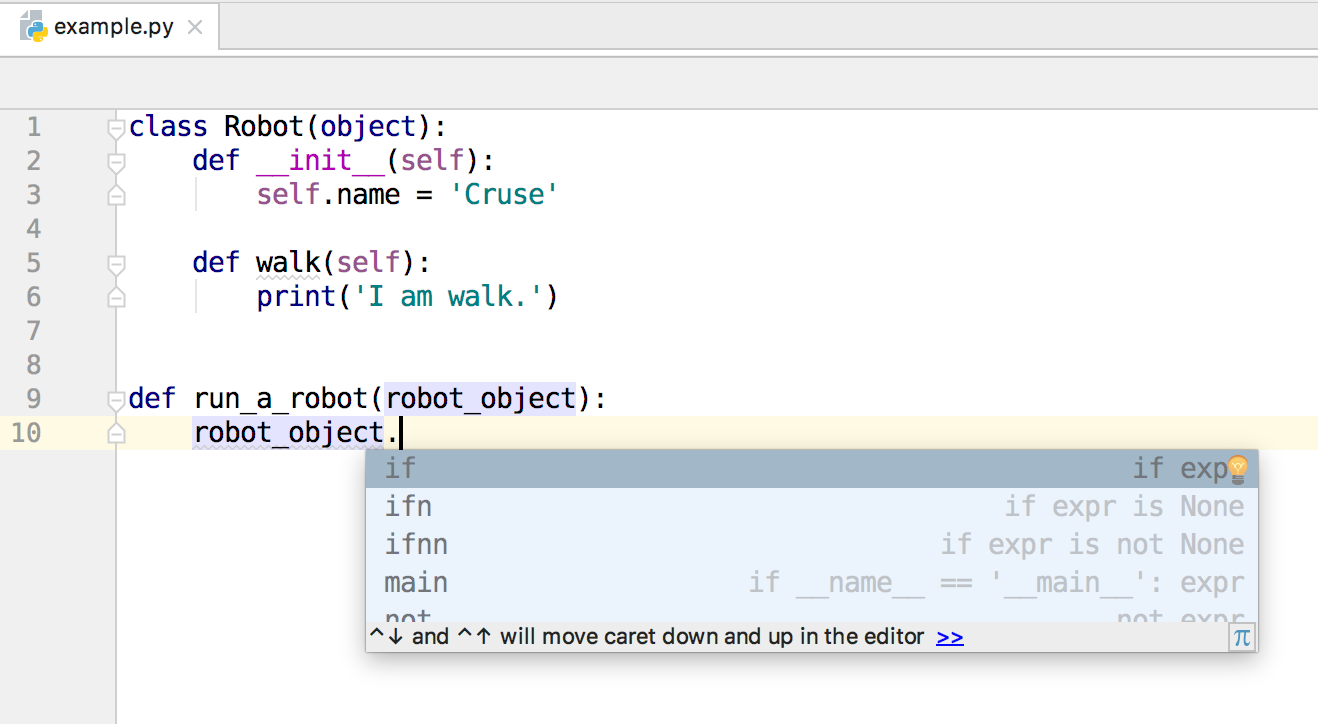
我定义了一个类Robot,这个类有一个属性name和一个方法walk。接下来我又定义了一个函数run_a_robot,这个函数接收一个参数robot_object,这个参数是Robot类的一个实例。在函数里面,我希望使用这个实例的属性和方法。但此时,可以看出,PyCharm的自动补全功能失效了。它不知道robot_object这个变量是什么东西,没有办法帮我补全这个实例的属性和方法名。如下图所示。
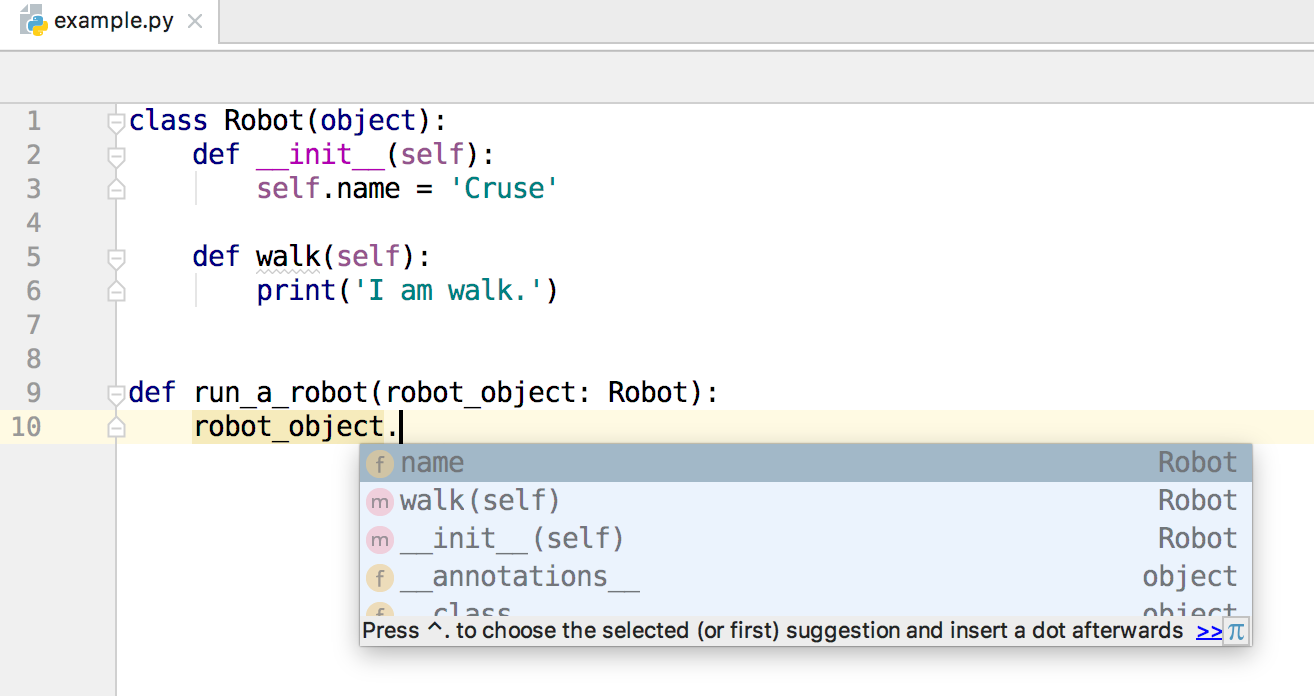
这个时候,如果你使用的是Python 3,那么你可以使用类型标注来告诉PyCharm,这个robot_object是Robot类的一个实例,从而使PyCharm提供自动补全。如下图所示。
类型标注的格式为
1 | 变量名: 类型 = 值 |
举一个例子:
1 | age: int = 24 # 定义一个变量age,它的类型为int,值为24 |
1 | def test(name: str, age: int=25, other_info: dict=None): # test函数接收两个参数,第一个参数name是str类型,第二个参数age是int型并且默认值为25,并且第三个参数other_info是字典,默认值为None |
关于类型标注的详细说明,请看这篇文章:https://www.kingname.info/2017/06/11/type-hints-in-python3/
2018.08
Docker的Log中不能显示Python print的内容,解决方法:
在Dockerfile 中添加一行:
1 | ENV PYTHONUNBUFFERED=0 |
添加以后就可以在Log中看到Python print出来的log了。
在Standalone-chrome找不到Chrome的问题,解决办法:
如果是普通Docker容器,可以使用
1 | -v /dev/shm:/dev/shm |
如果是Docker Swarm,需要:
1 | --mount-add type=tmpfs,dst=/dev/shm,tmpfs-size=2147483648 |
由于docker中为root用户,因此在Selenium中启动Chrome的时候,需要加–no-sandbox参数,否则会报错。
1 | chrome_options = webdriver.ChromeOptions() |
在MySQL中查询重复行:
1 | select host_id, count(host_id) from host_info group by host_id, platform having count(host_id) > 1 |
在MySQL中移除重复行:
1 | delete t1 from host_info t1 inner join host_info t2 where t1.id<t2.id and t1.host_id = t2.host_id and t1.platform = t2.platform |
使用Python的logging模块时,不仅要给StreamHandler设定Level,还需要给Logger设level,只有这样才能正常输出内容到控制台。
在创建Docker Service的时候,需要指定参数--network=host这样才能使用主机的网络。如果不使用这个参数,那么就无法访问有防火墙限制的局域网中的其他服务器。
2018.07
为Git设置socks5代理:
1 | git config --global http.proxy 'socks5://127.0.0.1:1080' |
2018.05
grep持续监控Log:
1 | tail -f file | grep --line-buffered my_pattern |
- 根据index读list,时间复杂度为O(1)但deque是O(n)
- 在两头插入数据,deque的时间复杂度为O(1), list为O(n)
- deque是一个双向链表,所以操作头尾非常简单。
- 随机往中间插入数据,deque与list的时间复杂度都是O(n)
2018.04
MongoDB的聚合查询中,$substr只能匹配ASCII的数据,对于中文要使用$substrCP
Flask的上下文对象current_app只能在请求线程里存在,因此它的生命周期也是在应用上下文里,离开了应用上下文也就无法使用。
1 | app = Flask('__name__') |
会报错:
1 | RuntimeError: working outside of application context |
此时可以手动创建应用上下文:
1 | with app.app_context(): |
扩展AWS的磁盘空间:
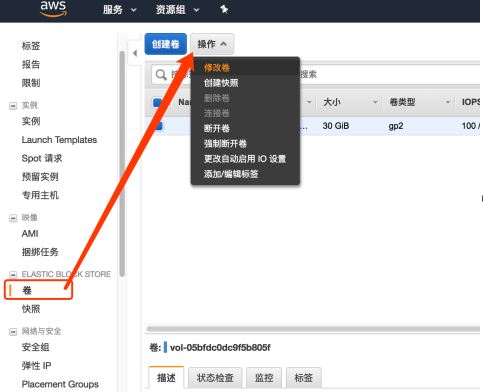
点击修改卷增加磁盘配额,SSH进入服务器,输入以下代码:
1 | lsblk #这条命令用来确定当前可用的磁盘空间小于磁盘配额 |
再次执行df -h可以看到已经使用了新的空间
2018.03
在Docker查看正在运行的容器是通过什么命令启动的:
1 | docker ps -a --no-trunc |
在全新的Ubuntu中安装pip:
1 | sudo apt-get update |
tar压缩文件的时候排除特定文件和文件夹:
1 | tar --exclude='./folder' --exclude='./upload/folder2' -zcvf /backup/filename.tgz . |
2018.02
在MongoDB使用自带的mongodump备份数据的时候,如果数据库设置了密码,那么在指定mongodump的--password 密码参数的同时,还必须指定--authenticationDatabase admin
2018.01
使用grep持续监控Log:
1 | tail -f file | grep --line-buffered my_pattern |
使用rsync通过SSH从服务器拉取数据:
1 | rsync -avzP [email protected]:Projects/sample.csv ~/sample.csv |
如果有SSH Key的话,使用下面的命令:
1 | rsync -avzP -e "ssh -i ~/sshkey.pem" [email protected]:Projects/sample.csv ~/sample.csv |
在Ubuntu中修改时区:
1 | sudo timedatectl set-timezone Asia/Shanghai |
使用XPath获取名称包含特定字符的属性的属性值:
1 | //span/img/@*[contains(name(), "src")] |
AWS在一年免费期间内,换机房不用给钱。先在老的实例生成AMI,再把AMI复制到新的城市,再从新城市的AMI创建实例。然后把老城市的实例彻底终结,取消老城市和新城市的AMI。全程不收费。
在Python中执行Shell命令并获取返回结果:
1 | import subprocess |
如果命令本身没有返回,则会抛出一个subprocess.CalledProcessError
在Shell中判断一个进程是否存在:
1 | if ps -ef | grep 进程名 | grep -v grep > /dev/null |
2017.12
firewalld对特定IP开放特定端口:
1 | firewall-cmd --permanent --zone=public --add-rich-rule='rule family="ipv4" source address="特定IP" port protocol="tcp" port="特定端口" accept' |
生成文件树并过滤特定文件或文件夹:
1 | tree -I '__pycache__|pyc|Logs' |
统计代码行数:
1 | find . -name "*.py" | xargs wc -l |
为pip设置代理:
1 | pip3.6 --proxy http://代理IP:端口 install -r requirements.txt |
为Git设置代理:
1 | RUN git config --global http.proxy http://代理IP:端口 |
为Ubuntu的apt-get设置代理:
1 | vim /etc/apt/apt.conf.d/01turnkey |
在里面插入一行:
1 | Acquire::http::Proxy "http://your.proxy.here:port/"; |
保存以后,下一次执行apt-get命令就会使用代理了。
2017.11
修改Elasticsearch默认的数据文件地址到/mnt/es文件夹,需要首先创建这个文件夹,然后为elasticsearch这个用户添加这个文件夹的权限:
1 | Chown -R elasticsearch:elasticsearch /mnt/es/ |
然后再修改elasticsearch的配置文件。
在postgres中,占位符是$1, $2而不是MySQL中的?
2017.10
使用urlpare从URL中获取Host:
1 | from urllib.parse import urlparse |
解压tar.gz压缩文件:
1 | tar zxvf 文件名 |
根据进程名字在Linux里杀进程。
1 | ps -ef | grep "进程关键字" | grep -v grep | awk '{print $2}' | xargs kill -9 |
在Python 的try ... except Exception ...中显示tracebook:
1 | import traceback |
输出如下:
1 | Traceback (most recent call last): |
这个功能在多层try ... except Exception ... 嵌套的时候特别有用。
2017.09
在macOS中直接复制文件路径,在Finder中选中文件,按下快捷键:Command + Option + C
以KB,MB,GB方式显示文件大小
1 | ls -lh |
删除超大文本文件的特定行数
1 | sed -e '10000,50000d' xxx.txt > new_xxx.txt //删除xxx.txt的第10000行到50000行的所有内容,并将结果保存到new_xxx.txt |
切分超大文本文件
1 | split -b 2G -d -a 2 deletelines.txt da //把超大文件切分为多个文件,每个文件2GB,前缀为da,后缀为2位数字 |
修改Linux当前用户密码
1 | passwd |
使用Python打开一个未知编码的文件:
1 | with open("your_file", 'rb') as fp: |
2017.08
在SSH + Tmux中,如果想复制,按住Alt或者Option键再选择就可以复制了。
关闭requests的SSL警告
1 | import requests |
在VIM中,Crtl + V Ctrl + A可以输出特殊符合^A,把A改为可以得到^M
2017.07
在Python中,pymongo的find方法返回的是一个生成器,只有在迭代的时候才会执行里面的具体代码去读MongoDB。但是在Golang的Mgo包中,如果想让Find返回一个迭代器而不是直接把所有结果全部返回,就需要手动指定:
1 | type xInfo struct { |
2017.06
在Golang中,使用MySQL的事务:
1 | // paraArray为一个channel,里面是更新所需要的参数 |
由于更新MySQL会锁表,因此使用多个goroutine来更新MySQL,效果可能还不如直接在主线程中更新来的高。
在Golang中,使用goroutine太多反而会导致性能下降。
2017.05
在Python中,可以使用>或者>=来判断一个集合是不是另一个集合的子集。只有是子集才会返回True
2017.04
在MongoDB中,通过_id来更新数据:
1 | from bson.objectid import ObjectId |
在Python 3中,计算两个日期相隔了多少秒:
1 | import datetime |
Scrapy中,通过覆写items.py中,每个item的__repr__方法,可以减少打印出来的Log信息。
1 | class XXXItem(Item): |
在VIM粘贴Python代码的时候,缩进会一不小心爆炸。为了避免这个问题,应该先在normal模式输入
1 | :set paste |
回车,再按i,再粘贴。这样Python的缩进就不会乱掉了。
Selenium的Debug级的Log有时候打得太多了,为了去掉Selenium的Debug Log又不影响其他部份的Debug Log,可以使用如下命令完成:
1 | import logging |
2017.02
To use the decorator, apply it as innermost decorator to a view function. When applying further decorators, always remember that the route() decorator is the outermost.
效率的关键就是不公平,80/20原则,刻意练习。
2017.01
HTML的<select></select>标签可以实现下拉选择框。
1 | <select class="form-control"> |
运行效果如下:
通过二进制的位操作,可以简化很多问题的分析。
例如现在有四个角色,分别为:读者,作者,编辑和管理员。有四个不同的权限使用四位的二进制数表示:
- 阅读权限:0001
- 写入权限:0010
- 修改权限:0100
- 删除权限:1000
每个角色的权限如下:
- 读者只能读,所以权限是0001
- 作者能读也能写,所以是0011
- 编辑能读能写能修改,所以是0111
- 管理员能读能写能修改能删除,所以是1111
要判断一个角色有哪些权限,人眼可以直接看对应的位置上面是0还是1,是0就是没有权限,是1就是有权限。在程序里面可以通过和对应权限的四位二进制数取位与操作。例如,0111编辑是否有写权限?因为0111 & 0010 = 0010 所以有写权限。只要角色的四位二进制数和权限的四位二进制数取位与,得到的结果还是权限的四位二进制数,那么就有这个权限。
正常情况下人有十根手指,所以一共可以计数1024个,但是一般在计数到第4个数的时候你就会挨打。明白二进制的自然知道我说的是什么意思。不明白二进制的,请看下面的动图:
Markdown在写作方面有非常好的优势,可以让写作的人不用关心格式,从而专注于要写的内容。但是Markdown不能进行缩进,这导致在一些大纲类的文本信息的显示上不太友好。Workflowy的出现可以解决这个问题。Workflowy只支持文本,界面极其简洁:
通过它来创建一个大纲,有助于理清思路。
在HTML的<form></form>表单中,有一个属性叫做action,它的值是空或者是一个URL的相对路径或绝对路径。如果为空,表单将会被提交到现在这个页面的URL;如果不为空,表单将会被提交到action的值对应的页面来处理。
理解这一点,那些喜欢在Flask中,把GET和POST写到一个Route,同时又要为GET带参数的人,需要特别注意。因为当你POST的时候,如果action不为空,参数可能会被丢失。
如果你想在局域网中共享一个文件,你可以通过Python 3快速完成:
- 打开终端或者CMD
cd进入你需要分享的文件所在的文件夹- 输入
python3 -m http.server回车 - 在另一台电脑上打开浏览器,输入上一台电脑的
ip地址:8000例如:192.168.2.13:8000 - 下载文件
在Python中,使用yield实现生成器。生成器的性质是只有在被迭代的时候才运行其内部的代码。这样可以大大降低内存的占用。除此之外,yield还可以接收参数供生成器内部使用。
1 | def generator(top): |
输出结果为:
1 | 0 |
以上的运行方式,和协程非常的相似。
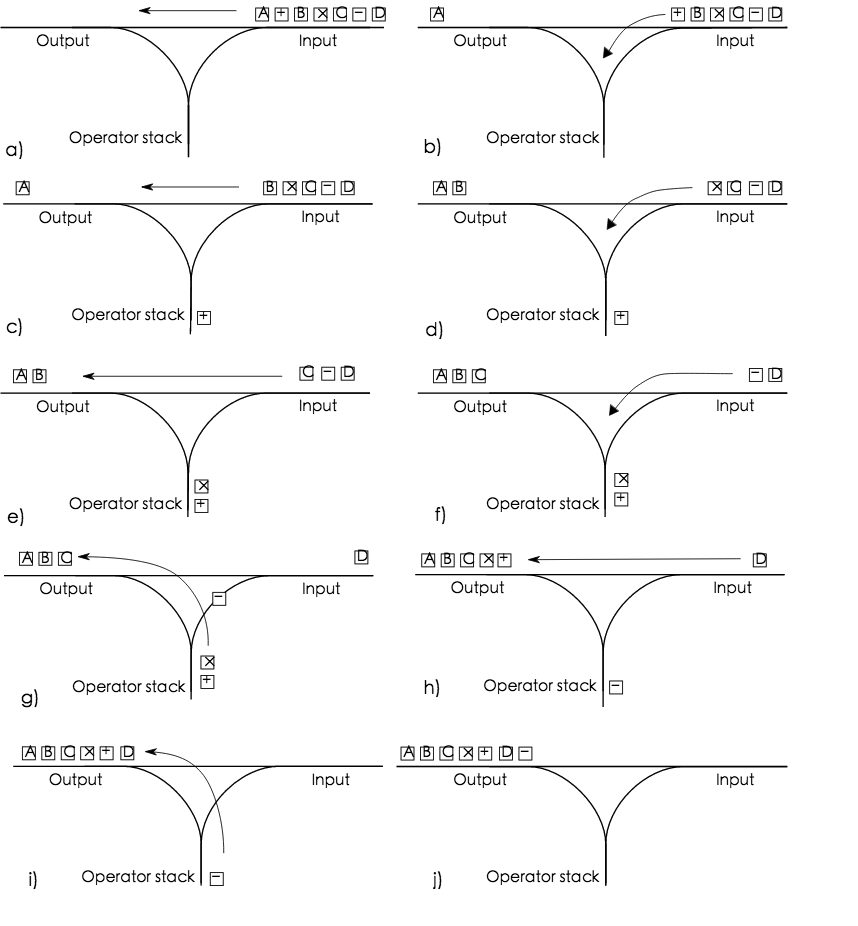
逆波兰式通过栈来实现对表达式的运算。例如:
中缀表达式: 5 + ((1 + 2) * 4) − 3
逆波兰式:5 1 2 + 4 * + 3 −
使用调度场算法可以将中缀表达式转换为逆波兰式。调度场算法是通过栈来实现的。操作数直接输出,符号需要判断优先级来判断应该直接压栈还是直接输出或者应该先将栈顶元素输出再压栈。